
LLM4N2: Giving words meaning with Neural Networks
Word2Vec, RNNs, usecases, their limitations, and what's next?

Hey everyone. Welcome back to LLM4N: LLM For Noobs!
A 16-part series designed to take you from zero to one in understanding LLMs.

In the last issue, we covered statistical techniques like N-gram models. We discussed how they work, why they work, and their limitations. Check it out if you haven’t yet.
We also hit a wall.
We concluded that N-grams struggle with two fundamental problems:
They are trapped within a tiny, fixed-context window, blind to the broader meaning of a sentence.
They treat words as meaningless symbols, unable to see that "cat" is closer to "kitten" than it is to "car."
To truly understand language, a machine needs to grasp that words have meaning and that this meaning is fluid, shaped by the words around them.
Today, we’re making a giant leap forward. We’re moving from simply counting words to truly understanding them. We’ll explore two of the foundational breakthroughs that paved the way for modern LLMs:
Word2Vec: The revolutionary technique that taught machines to map words to a geometric “meaning space.”
Recurrent Neural Networks (RNNs): The first architecture that gave a neural network a form of memory to understand sequence and order.
Let’s dive in!
Breaking down Word2Vec
The first big idea we need to tackle is the Distributional Hypothesis.
It’s a fancy term for a beautifully simple and powerful concept: "A word is known by the company it keeps". In other words, words that consistently appear in similar contexts tend to have similar meanings. "Dog" and "cat" often appear in sentences with words like "pet," "food," and "house," while "cabbage" and "asynchronously" probably don't.
This is the core intuition behind word embeddings, and the most famous algorithm for creating them is Word2Vec. Instead of representing words as distinct, isolated symbols (like N-grams do), Word2Vec learns a dense vector, a list of numbers, for each word.
Think of a massive magical, multi-dimensional map of language. On this map, every single word is a specific location. This algorithm’s job is to arrange all the words on this map so that semantically similar words become neighbors. It’s a geometric space where distance is a proxy for semantic similarity.
You can read the original paper here.
The figure below should give you an idea of what it looks like in a 3D space.
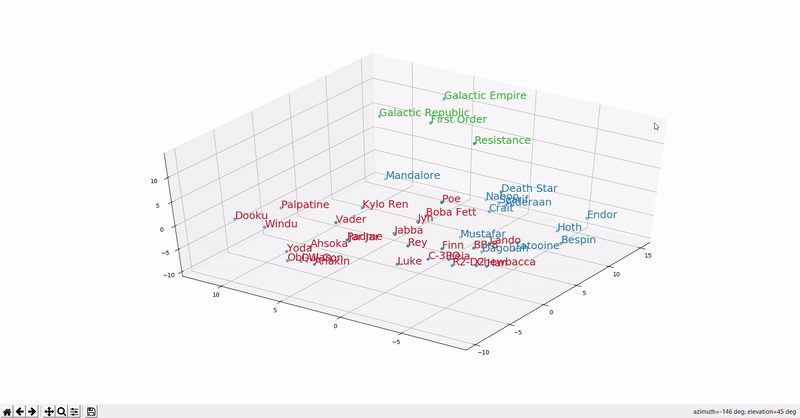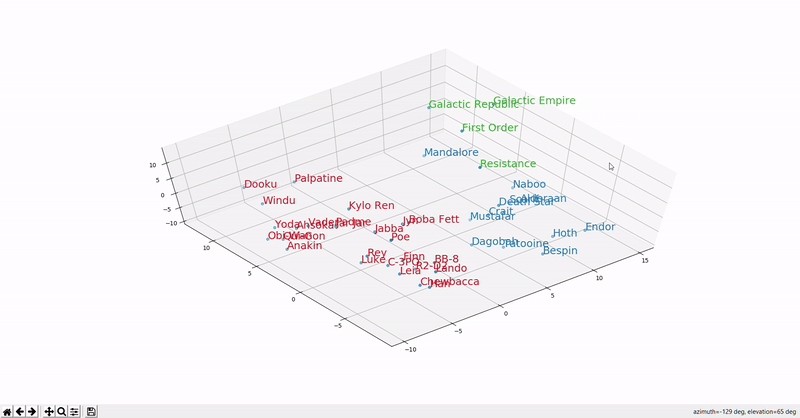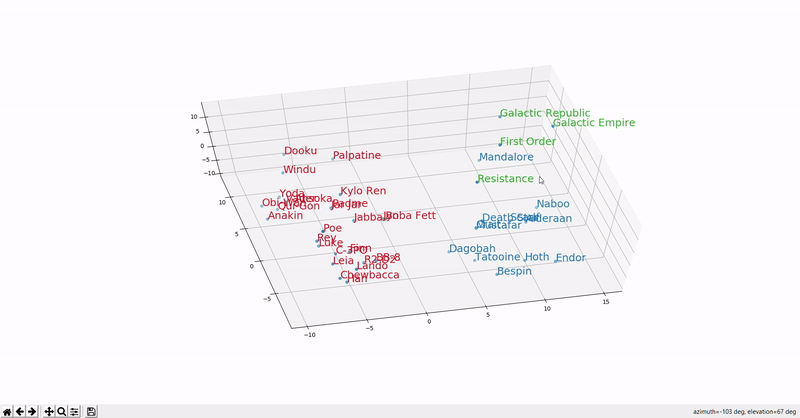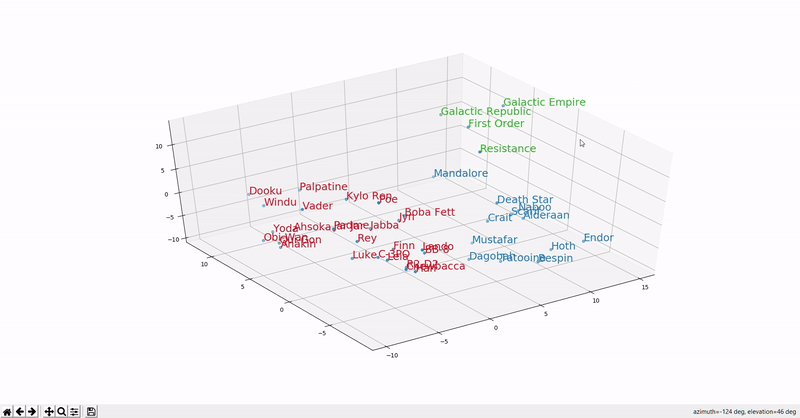
As you can see, the similarly colored words are closer to each other, suggesting they are used in the same context.
The “aha!” moment with vector arithmetic
This “meaning map” has a magical property. It captures abstract relationships between words as consistent directions or offsets in the vector space. This leads to the most famous and brilliant example of word embedding magic:
This is actually very very cool. We can perform arithmetic on words!
This works because word2vec is trained to place words in the vector space such that their relationships can be modeled linearly. The training process learns vectors where the difference v_king - v_man captures the same relational offset as v_queen - v_woman. What does this mean?
This means that the vector space is not a jumble of points; it has a consistent, meaningful structure that mirrors the relational structure of language itself!
But...how does it learn?
While the exact details of the architecture are out of scope of this discussion, let’s take a brief look at how it works.
Word2Vec is not a single algorithm. It’s a framework that includes two distinct shallow neural network architectures. They approach the learning task from opposite directions, but both are designed to master the “fill-in-the-blanks” game of language.
Continuous Bag-of-Words (CBOW): This model plays a “guess the missing word” game. It takes the surrounding context words (e.g., "The cat sat on the ___") and its goal is to predict the missing central word ("mat"). The "bag-of-words" part means it treats the context words as an unordered collection; their vectors are typically averaged together to form a single representation of the context, which is then used for the prediction. CBOW is generally faster to train and performs well for frequent words.
Skip-Gram: This model does the opposite. It takes a single word (e.g., "cat") and tries to predict its surrounding context words ("The," "sat," "on," "the," "mat"). For each input word, it creates multiple training examples—one for each word in its context window. This makes it slower to train, but it's excellent at learning high-quality representations for rare words, as it gets more "practice" out of each instance it sees.
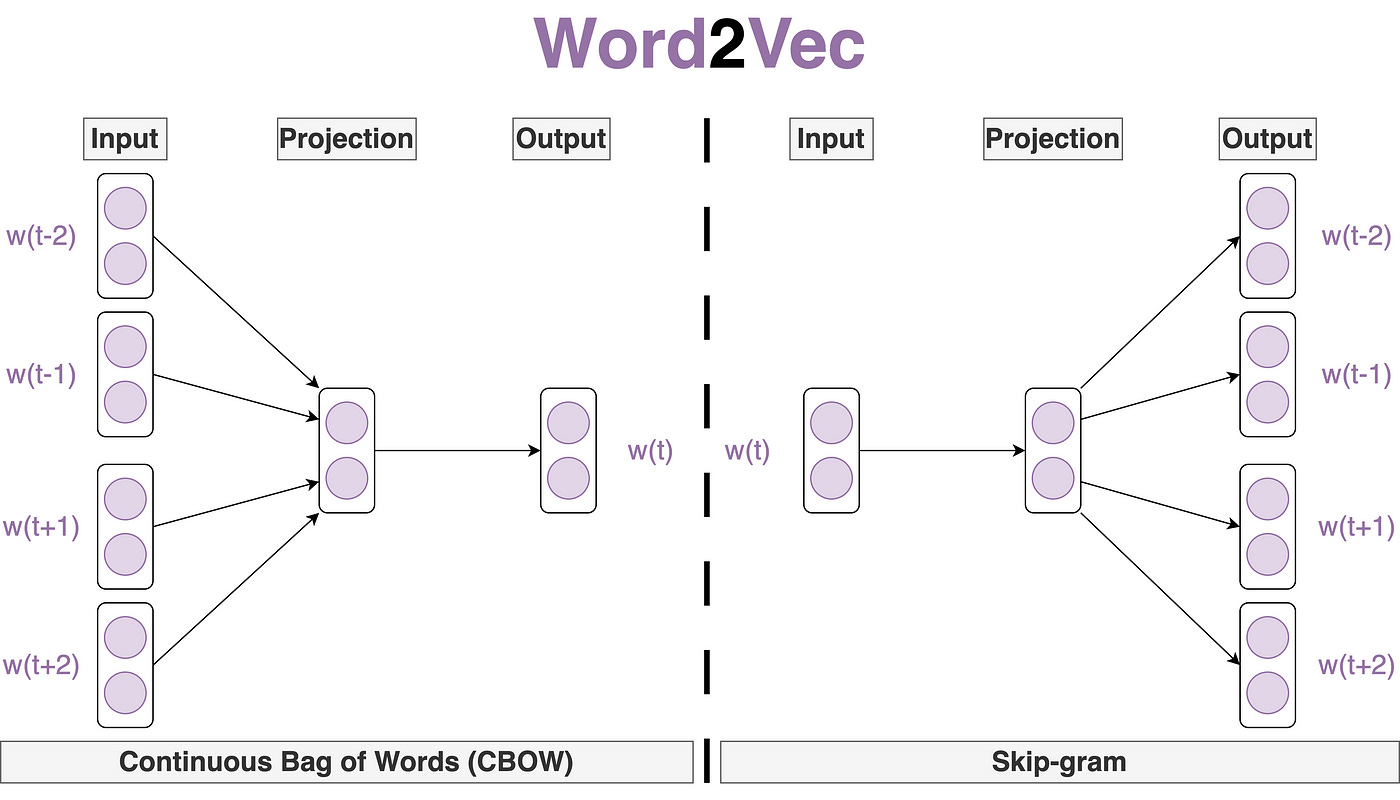
Word2Vec was a monumental step. It gave us a way to represent words not as isolated tokens, but as rich, relational concepts. With that we partially solved one of the main problems we started with: Meaning of words. But it still has a blindspot. A simple word2vec model sees “man bites dog” and “dog bites man” as very similar because they contain the same words. To solve that, we need a network with memory.
That brings us to tackle the next challenge.
A network that remembers - RNNs
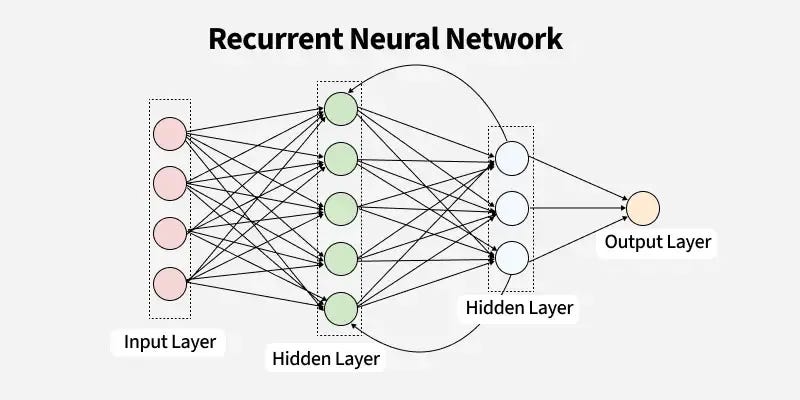
To truly understand language, we need an architecture that can process information sequentially. Unlike a standard feedforward network where information flows only in one direction (input → output), a RNN has a loop. This simple but powerful recurrent connection allows information to persist, flowing from one step of the sequence to the next.
The key component that makes this possible is the hidden state.
The best way to think of the hidden state is as the network's memory or a running summary. Imagine you're reading a story. You don't just process each word in isolation; you maintain a mental summary of the characters, the plot, and what's happened so far.
This is exactly what an RNN does. At each step (or "time step"), it processes a new word from the sequence and combines it with its memory from the previous step. It then updates its memory and produces an output. This updated memory, the new hidden state, is then passed on to the next step. This chain-like nature allows the RNN to "remember" what it has seen earlier in the sequence and use that context to inform its understanding of the current word
Little bit of math
For those who want to peek under the hood, the operation of a simple RNN is governed by two core equations. (have to paste images since substack does not have latex support)

The real power comes from the fact that the weight matrices are the same for every single time step. This parameter sharing is a crucial design choice. It allows the RNN to handle sequences of any length and generalize what it learns about language patterns across different positions in the text.
So...what’s the catch?
So, we've given words meaning with word2vec and given our network memory with RNNs. Problem solved, right? Not quite. These foundational models, as revolutionary as they were, have their own critical limitations that paved the way for the next generation of architectures.
Word2Vec’s blind spot
A major flaw in word2vec is that it assigns a single, static vector to each word. This is a significant problem for polysemous words → words with multiple meanings.
Consider the word “bank”. In the sentences:
- “He deposited the check at the bank”
- “The river bank was eroded”
The word "bank" has two completely different meanings. However, word2vec will produce the exact same vector for "bank" in both cases. The model has no way of using the immediate context ("check" vs. "river") to understand which meaning is intended.
RNN has a remembering problem
The bigger issue lies with the simple RNN. While it can theoretically remember information across long sequences, in practice, it suffers from a severe short-term memory problem. This is due to the infamous vanishing and exploding gradient problem.
Intuitive Explanation: Think of it like a game of "Chinese whispers" or "telephone". When an RNN is trained, the error signal from the end of a sentence has to be passed all the way back to the beginning to update the weights. For a long sentence, this is like whispering a message down a very long line of people. By the time the message (the error signal) reaches the start of the line, it's often distorted or has faded to nothing.
Technically, these are called:
Vanishing gradient: The signal becomes so weak that the network doesn’t learn from the early parts of the sequence. It effectively forgets the beginning of the sentence because the feedback is too faint to make meaningful corrections.
Exploding gradient: The opposite can also happen. The signal can get amplified at each step, becoming so massive that it destabilizes the entire learning process, causing the model's weights to fluctuate wildly.
Why does this happen?
This happens because training an RNN involves a process called Backpropagation Through Time (BPTT), where gradients are calculated by repeatedly multiplying matrices together—once for each time step. The gradient signal is repeatedly multiplied by the recurrent weight matrix (W_hh). If the largest eigenvalue of this matrix is less than 1, the signal will shrink exponentially towards zero (vanish). If it's greater than 1, the signal will grow exponentially (explode). This mathematical instability is an inherent flaw in the simple RNN's design.
Okay...what’s next then?
So far, we understood how Word2Vec and RNNs worked briefly, what problems they solved, but we still aren’t quite there yet. Are we?
We moved from counting words to representing meaning and from static analysis to processing sequences. These innovations solved the core problems of N-grams and laid the essential groundwork for the powerful models we have today.
But as we’ve seen, they are not the final answer. the inability of Word2Vec to handle multiple meanings and the simple RNN’s unreliable memory were the next great challenges for the field.
How do you build a network that can selectively remember and forget information, allowing it to maintain context over hundreds or even thousands of steps?
That’s where Long-Short Term Memory Networks (LSTM) come in with a special mechanism called “gates”. And that’s what we are going to cover in the next issue!
Stay tuned for the next issue of LLM4N, where we’ll understand how LSTMs work and their gating mechanism!
Resources
Well, this was a brief explainer. But if you want a more hands-on understanding of Word2Vec, read the paper, and do Assignment 1 of CS224N.