

So…you must have written a SQL query, hit ‘Run,’ and the data you want pops up. Job done, right?
Maybe not…
Just because a query works doesn’t mean it’s good. You can think of it like giving directions. You could tell a friend to drive from Place A to Place B and they might get there by way of Place C. They completed the task but it was a slow expensive and painful trip.
A poorly written query does the exact same thing to your database. It takes the scenic route, burning through resources, slowing down your app, and increasing your cloud bill. This guide is about showing you several ways of how to write the an optimized query.
Lets start!
SQL query optimization is the process of improving query performance to ensure faster execution and more efficient use of resources (like CPU, memory, and I/O). While modern databases (Azure SQL, Snowflake, Databricks, etc.) have built-in optimizers, writing well-structured queries is crucial for achieving peak performance. A slow query isn’t just an inconvenience, it can cripple application performance and delay critical reports
But why do we need to optimize the query?
Cost Savings: In cloud platforms like Snowflake or BigQuery, every second of compute time costs money. A query that runs in 5 seconds instead of 5 minutes can translate to hundreds or thousands of dollars saved annually.
User Experience: For applications, the difference between a 200ms query and a 3-second query is the difference between a happy user and a frustrated one who closes the tab.
Faster Decisions: For analysts, faster queries mean faster reports, allowing the business to react to market changes more quickly
Why Queries Run Slow: Common Pitfalls
Understanding the root cause of a slow query is the first step. The most common culprits include:
Full Table Scans: The database has to read every single row in a table because it can’t find a more efficient path (like an index).
Inefficient Joins: Joining large tables without proper filtering or on non-indexed columns.
Missing or Poor Indexes: The absence of indexes on columns used frequently in where, join, or order by clauses.
Non-SARGable Queries: Using functions or like with a leading wildcard (%word%) on an indexed column, which prevents the database from using the index.
Over-fetching Data: Selecting all columns (select) when only a few are needed.
Complex Subqueries: Using multiple or correlated subqueries that execute repeatedly.
Fundamental Optimization Techniques
These are some of the best practices that should be applied to almost every query you write.
“UNION ALL” is Faster Than “UNION”
“Union” implicitly performs a “Distinct” operation to remove duplicate rows, which requires sorting and comparing the datasets. If you know the datasets are unique or you don’t care about duplicates then “Union All” is significantly faster because it simply concatenates the results.
Slow (Union):
SELECT user_id, user_name FROM active_users
UNION
SELECT user_id, user_name FROM recently_registered_users;Fast (Union All): When duplicates are not a concern.
SELECT user_id, user_name FROM active_users
UNION ALL
SELECT user_id, user_name FROM recently_registered_users;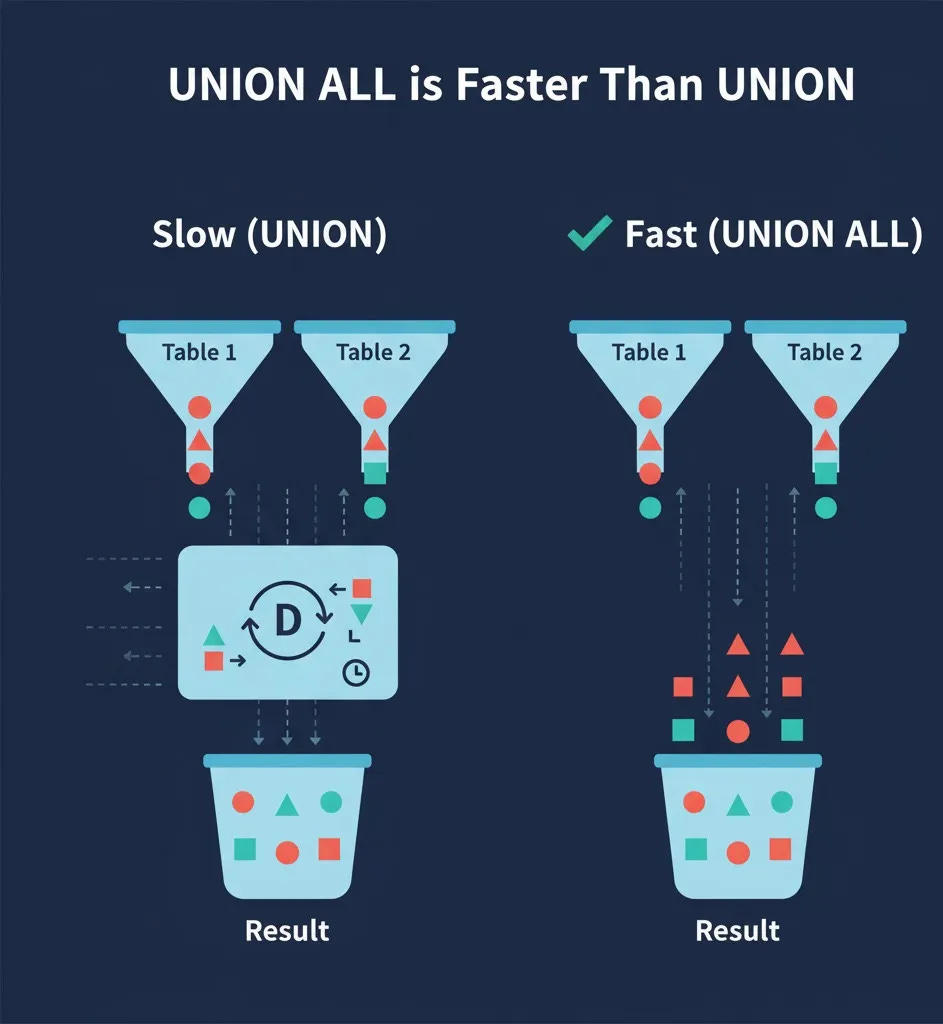
Be Specific with “SELECT”
Always specify the columns you need instead of using “Select ” . This reduces the amount of data transferred from the database to the client.
Before: Fetches all data, including columns you don’t use.
SELECT * FROM products;After: Fetches only the required product ID and name, reducing data transfer.
SELECT product_id, product_name FROM products;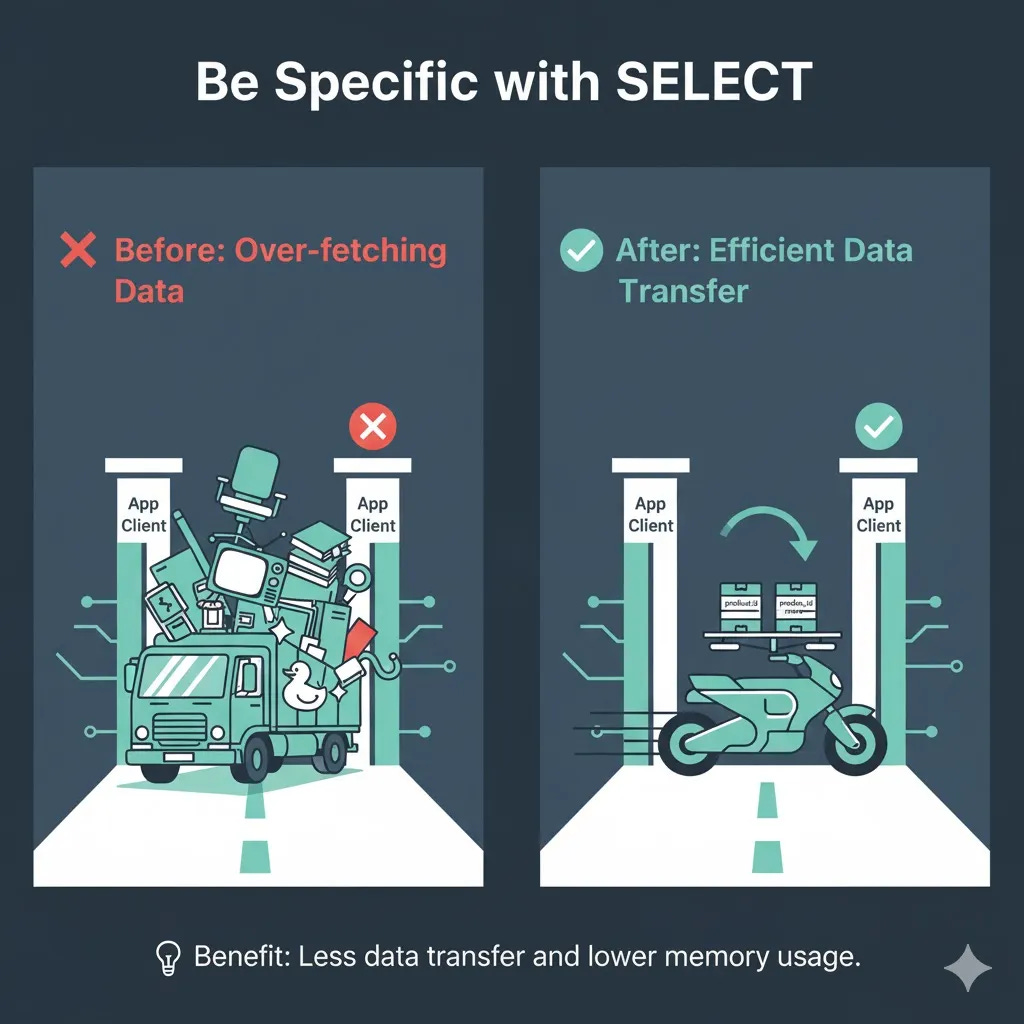
Filter Early and Reduce Your Dataset
Emphasize the principle of making your dataset as small as possible as early as possible. This means using the “where” clause to its full potential before resorting to “having”
Inefficient (Having): The grouping and aggregation happen before filtering.
SELECT region, SUM(sales_amount)
FROM sales
GROUP BY region
HAVING region = ‘North’;
Efficient (Where): The data is filtered before the expensive aggregation.
SELECT region, SUM(sales_amount)
FROM sales
WHERE region = ‘North’
GROUP BY region;
Use Indexes Effectively
Indexes act as a table of contents allowing the database to find data quickly without scanning the entire table. Create indexes on columns used for filtering, joining, and sorting.
An index speeds up data retrieval on the indexed column.
Before (No Index): A query filtering by an un-indexed “category” column forces a full table scan.
SELECT product_name, price FROM products WHERE category = ‘Electronics’;
After (Creating an Index): First, create the index. All subsequent queries using the “category” column in the “where” clause will be significantly faster.
Create the index once
CREATE INDEX idx_product_category ON products(category);
This query is now fast
SELECT product_name, price FROM products WHERE category = ‘Electronics’;
Caution: Don’t over-index. While indexes speed up reads (”select”), they slow down writes (”insert”, “update”, “delete”) because the index also needs to be updated.
Write SARGable Queries
A query is “SARGable” (Search ARGument-able) if the database engine can use an index to speed it up. Avoid applying functions to indexed columns in your “where” clause.
Avoid using functions on columns in the “where” clause.
Before (Non-SARGable): The “Year()” function prevents the database from using an index on “order_date”.
SELECT order_id, customer_name FROM orders WHERE YEAR(order_date) = 2025;
After (SARGable): Using a date range allows the database to use an index on “order_date” for a fast seek.
SELECT order_id, customer_name FROM orders
WHERE order_date >= ‘2025-01-01’ AND order_date < ‘2026-01-01’;
Benefit: Allows the optimizer to perform an efficient index seek instead of a full table scan.
Prefer “JOINS” Over Subqueries
Rewriting subqueries especially correlated ones as “Join” often results in better performance because it allows the optimizer to create a more efficient execution plan.
Before (Correlated Subquery): The inner query runs once for every single row in the “employees” table.
SELECT employee_name
FROM employees e
WHERE e.dept_id = (SELECT d.dept_id FROM departments d WHERE d.dept_name = ‘Sales’);
After (Join): The tables are joined once which is far more efficient.
SELECT e.employee_name
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_name = ‘Sales’;
Benefit: Joins are generally more efficient and readable.
Use CTEs for Readability and Reusability
For complex logic or to avoid repeating a subquery, use a Common Table Expression (CTE). This makes the query cleaner and often helps the optimizer.
Before (Messy Subquery): Finding all employees who work in a location managed by ‘Lee’.
SELECT * FROM employees
WHERE dept_id IN (SELECT dept_id FROM departments WHERE location_id =
(SELECT location_id FROM locations WHERE manager = ‘Lee’));
After (Clean CTE): The logic is broken into readable and logical steps.
WITH lee_locations AS (
SELECT location_id FROM locations WHERE manager = ‘Lee’
),
lee_departments AS (
SELECT dept_id FROM departments WHERE location_id IN (SELECT location_id FROM lee_locations)
)
SELECT * FROM employees WHERE dept_id IN (SELECT dept_id FROM lee_departments);
Benefit: Improved readability and easier maintenance.
Diagnosing Performance: The Execution Plan
The single most important tool for optimization is the execution plan. It is the database’s roadmap for how it will execute your query.
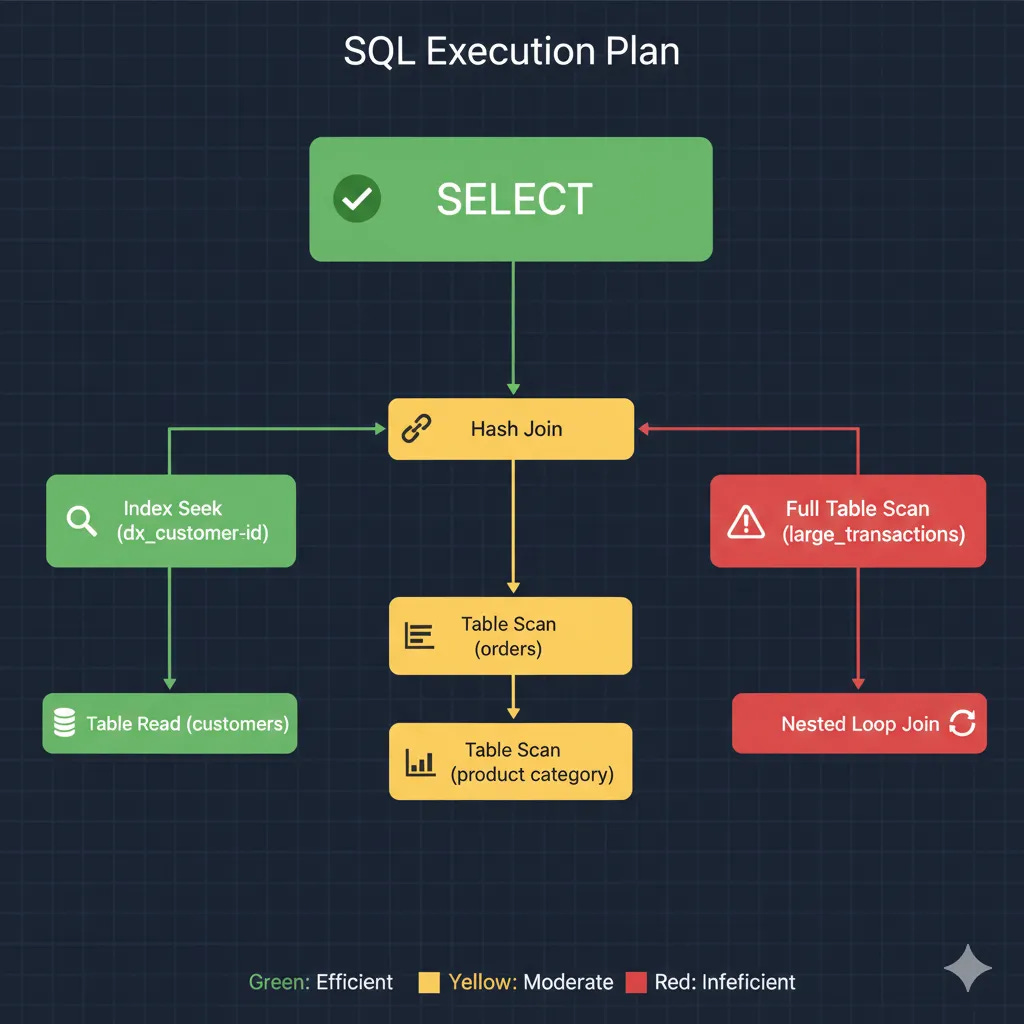
As the plan above shows, the database visualizes its steps. Your goal is to eliminate the red-flag operations and favor the highly efficient green ones.
Command: Use EXPLAIN (MySQL, PostgreSQL) or EXPLAIN PLAN (Oracle) before your query.
What you have to Look For:
Good Signs: Index Seek, Index Scan. These are fast and efficient.
Warning Signs: Full table Scan, Nested Loop Join (on large tables). These are your primary bottlenecks.
EXPLAIN ANALYZE
SELECT e.ename, d.dept
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept = ‘Finance’;
Tip: Analyzing the plan tells you exactly where the bottleneck is, removing the guesswork from optimization.
Advanced Optimization Strategies
1. Table Partitioning
For very large tables, you can partition them into smaller, more manageable pieces based on a key like a date. When you query for a specific date range the database only scans the relevant partitions.
This example partitions a large “sales” table by year. When you query for a specific year, the database only scans that partition.
Example (Table Creation):
CREATE TABLE sales (
sale_id INT,
sale_date DATE NOT NULL,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (YEAR(sale_date));
Example (Efficient Query): This query will only scan the data partition containing records from 2025
SELECT SUM(amount) FROM sales WHERE sale_date BETWEEN ‘2025-01-01’ AND ‘2025-12-31’;
2. Materialized Views
This creates a pre-computed summary table. Querying the view is much faster than recalculating the summary from the raw data every time.
Example (View Creation):
CREATE MATERIALIZED VIEW sales_summary AS
SELECT
region,
product_category,
SUM(amount) AS total_sales,
COUNT(*) AS number_of_sales
FROM sales
GROUP BY region, product_category;
Example (Fast Query): Getting the total sales for electronics in the ‘North’ region is now instantaneous.
SELECT total_sales FROM sales_summary WHERE region = ‘North’ AND product_category = ‘Electronics’;
3. Update Statistics
Database optimizers rely on statistical information about your data to make smart decisions. Sometimes these statistics become stale. Running a command to update them can dramatically improve query plans. This simple command tells the database to re-analyze the data in a table, which helps its optimizer make better decisions.
Example Command (PostgreSQL / MySQL):
ANALYZE TABLE employees;
Example Command (SQL Server):
UPDATE STATISTICS employees;
4. Use Query Hints (Wisely)
A hint is a direct instruction to the database optimizer, overriding its default behavior. Use them sparingly and only when you are certain you know a better execution plan than the optimizer.
Example (Forcing an Index): This tells the database to use the “idx_emp_dept” index, even if it thinks another plan is better.
SELECT /*+ INDEX(e idx_emp_dept) */ employee_name, salary
FROM employees e
WHERE e.dept_id = 50;
Conclusion
SQL optimization is more than a technical skil its more like a mindset. It’s about treating database resources with respect and writing code that is not only correct but also elegant and efficient. By moving from simply getting the right answer to getting it in the best way possible you elevate yourself from a query writer to a true performance architect.